
什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的,是一种数据结构。它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是高效的插入和查询,而且非常节省空间,缺点是hash 碰撞造成的误识别率和删除困难。
使用场景
一般使用较多的场景就是避免缓存穿透,比如数据库Id一般都是从1开始,我们根据Id查询商品信息,默认商品信息都是在Redis中,如果有人传 -1,这样就会使查询不走缓存而是直接走数据库,这时候就相当于出现了缓存穿透。
可以参考一下我之前写的文章:传送
布隆过滤器的原理
当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。如下图所示:
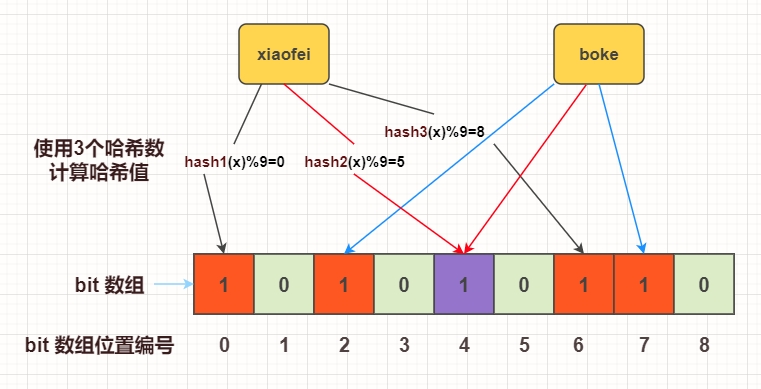
bit 数组长度是9,散列函数个数是3,存入 xiaofei和boke这两个元素。这两个元素经过三次哈希函数生成3个哈希值,并映射到bit数组的不同的位置,并置为1。查询的时候进来一个xiaofei,计算它三次哈希值并找到对应的bit数组位置编号,看看是否为1,若为1表示存在,否则不存在。
当布隆过滤器保存的元素越多,被置为 1 的 bit 位也会越来越多,误判的可能性也会增加,因为多个元素之间会产生更多的位重叠。因此,布隆过滤器适合于需要快速判断一个元素可能在集合中但不需要绝对准确性的场景,当查询一个元素时,如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在。
布隆过滤器不支持删除:因为如果有多个元素都分配在位置4上,如果把位置4的值从1变成了0,会影响其他元素的判断的。我们可以通过定时重新构建布隆过滤器两种方案实现删除元素的效果。
代码实现
pom依赖;
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
代码:
public static void main(String[] args) {
// 预期插入数量
long capacity = 1000L;
// 错误比率
double errorRate = 0.0001;
// 创建BloomFilter对象,需要传入Funnel对象,预估的元素个数,错误率
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), capacity, errorRate);
// put值进去
for (long i = 0; i < capacity; i++) {
bloomFilter.put(String.valueOf(i));
}
// 统计误判次数
int count = 0;
// 在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (long i = capacity; i < capacity * 2; i++) {
// 判断元素是否存在
if (bloomFilter.mightContain(String.valueOf(i))) {
count++;
}
}
System.out.println(count);
}
总结:
1、由上可知,它的原理就是利用多个哈希函数,将一个元素映射成多个位,然后将这些位设置为1,当查询一个元素时,如果这些位都是为1,则认为元素可能存在于集合中,否则肯定不存在。
2、误判率取决于哈希函数数量、位数组大小和集合元素数量,可以通过调整参数来平衡误判率和空间占用。
3、布隆过滤器无法删除已经添加的元素,可能会影响其他元素的判断结果。
在线布隆过滤器计算器:传送






当前共有 0 条评论